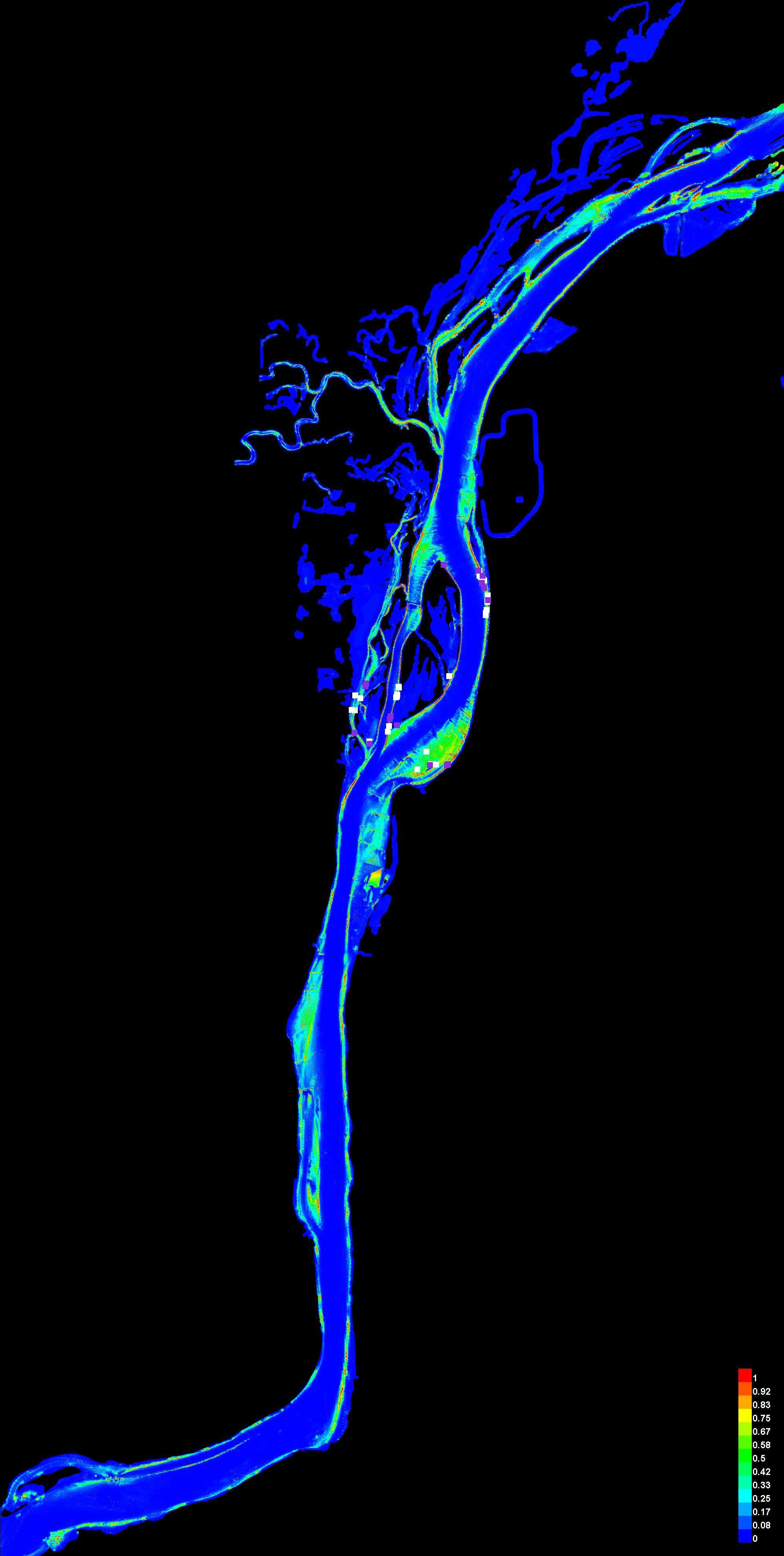
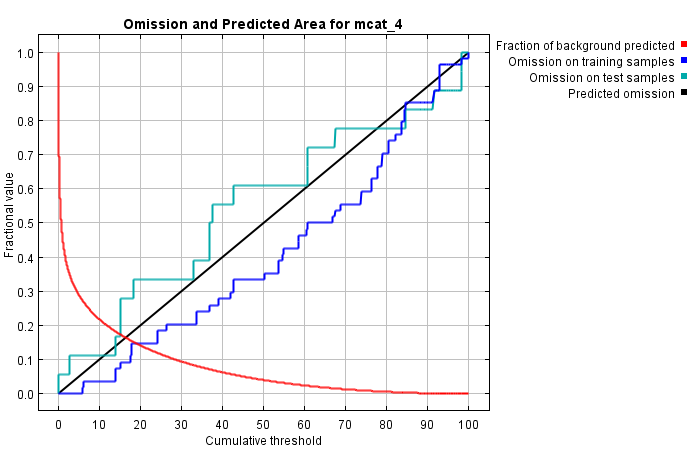
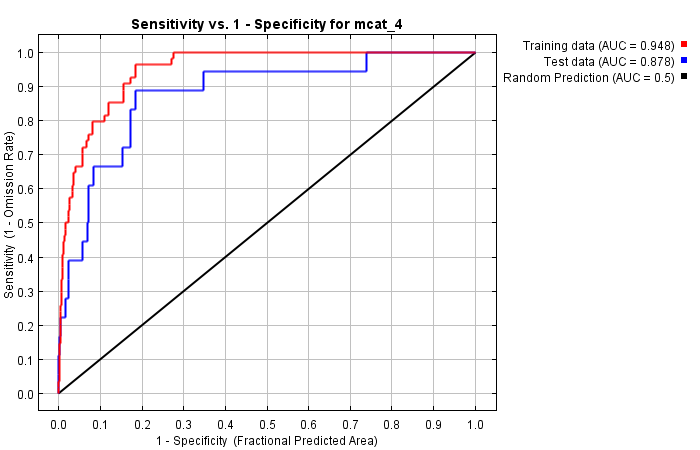
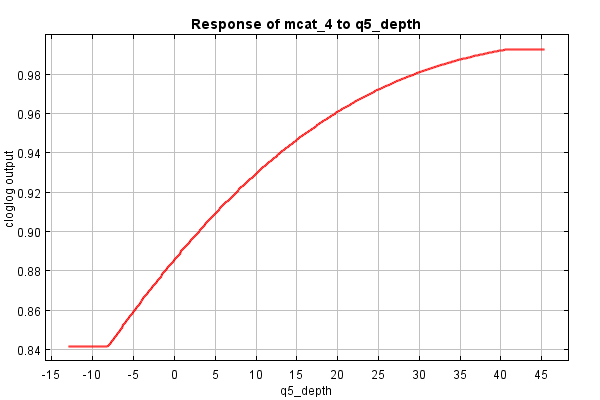
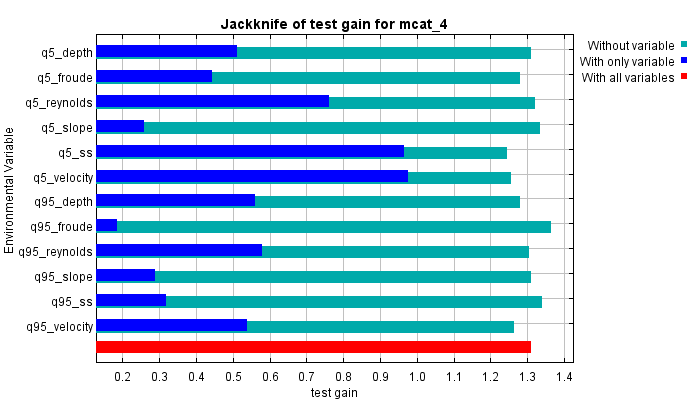
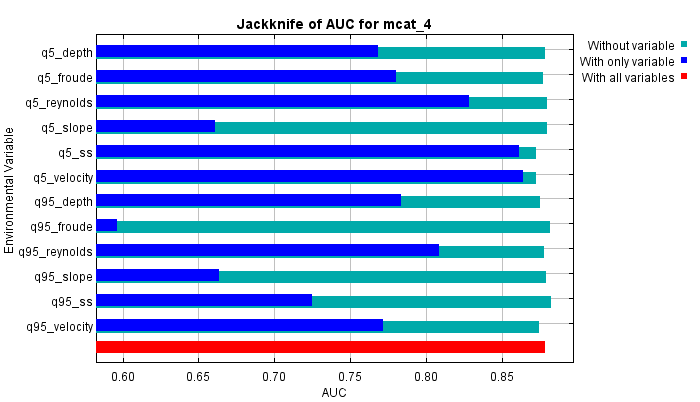
| Cumulative threshold | Cloglog threshold | Description | Fractional predicted area | Training omission rate | Test omission rate | P-value |
|---|
| 1.000 | 0.016 | Fixed cumulative value 1 | 0.454 | 0.000 | 0.056 | 1.518E-5 |
| 5.000 | 0.091 | Fixed cumulative value 5 | 0.289 | 0.000 | 0.111 | 1.905E-7 |
| 10.000 | 0.165 | Fixed cumulative value 10 | 0.218 | 0.037 | 0.111 | 2.484E-9 |
| 5.751 | 0.104 | Minimum training presence | 0.275 | 0.000 | 0.111 | 8.954E-8 |
| 17.677 | 0.255 | 10 percentile training presence | 0.156 | 0.093 | 0.278 | 1.277E-7 |
| 18.946 | 0.267 | Equal training sensitivity and specificity | 0.148 | 0.148 | 0.333 | 8.576E-7 |
| 13.830 | 0.214 | Maximum training sensitivity plus specificity | 0.183 | 0.037 | 0.111 | 1.703E-10 |
| 15.228 | 0.230 | Equal test sensitivity and specificity | 0.173 | 0.074 | 0.167 | 1.738E-9 |
| 13.830 | 0.214 | Maximum test sensitivity plus specificity | 0.183 | 0.037 | 0.111 | 1.703E-10 |
| 3.897 | 0.073 | Balance training omission, predicted area and threshold value | 0.314 | 0.000 | 0.111 | 6.625E-7 |
| 13.019 | 0.205 | Equate entropy of thresholded and original distributions | 0.190 | 0.037 | 0.111 | 2.946E-10 |